
Evaluating Vocality in Orchestrated and Mixed Works
Evaluating Vocality in Orchestral and Mixed Works
ACTOR Research-Creation Project Report
Published: June 25, 2025
Louis Goldford (Columbia University), Jason Noble (Université de Moncton), Jay Marchand Knight (Concordia University), Etienne Abassi (McGill University), Gabriel Couturier (Université de Montréal), Theodora Nestorova (Viterbro University), Caroline Traube (Université de Montréal)
Abstract
Evoking the human voice through instrumental music has been a perennial goal for composers, appearing in traditional and historical performance instructions such as cantabile and contemporary practices such as formant modeling (e.g., Jonathan Harvey, Speakings, 2008; Peter Ablinger, Deus Cantando, 2009). Performers also make extensive use of vocal metaphors in their discourse (Healy, 2018). But do general listeners perceive instrumental music in terms of vocal qualities or metaphors? Here we address this question by asking listeners to rate their perceptions of vocality in music intended to emulate it. Listeners provided real-time continuous slider data indicating how “voice-like” they perceived our repertoire excerpts to be. These excerpts included contemporary vocal mimesis techniques, traditional approaches to vocality, and control stimuli (i.e., music that is materially similar to the memetic excerpts but not explicitly intended to evoke the voice). This study provides perceptual validation for a phenomenon that has been important to musicians for centuries. Based on these findings, a new composition by Louis Goldford has been commissioned and is currently in development, incorporating the vocality features identified in our analysis. Although the composition has not yet been performed, it represents a future application of our methodology within a creative practice.
Keywords
Mimesis, contemporary music, vocality, perceptual effectiveness, orchestration
Introduction
Western art music has historically drawn upon the human voice as a central model for instrumental expression. From the cantabile ideals of eighteenth- and nineteenth-century performance to the evocative titling of works like Bach’s Arioso (BWV 156) or Mendelssohn’s Lieder ohne Worte, to a recent body of works inspired by contemporary speech analysis and signal processing, instrumental music has long aspired to mimic the specific properties of the sung and spoken human voice. Pianists from Chopin to the Schumanns were associated with a so-called “singing style” of playing, while pedagogical traditions and performance maxims, such as “all Mozart is opera”, continue to underscore the enduring influence of specifically vocal paradigms and models (Day-O’Connell, 2014; Roudet, 2014; Healy, 2018).
Where earlier traditions often idealized a generalized notion of lyricism and song, contemporary works tend to focus on the nuances of particular voices and utterances, frequently mediated through digital technologies (Noble, 2022). Rather than striving for a broadly “singing” instrumental style, many recent composers have turned to the granular details of human vocal production as a compositional resource, the contours of a whispered consonant, the graininess of a growl, or the breath‐rhythm of conversational speech (Rabiner & Schafer, 2010; Patel, 2010). This shift reflects not only a more atomized approach to vocality, but also a heightened sensitivity to the expressive possibilities of idiosyncratic timbres and microtemporal gestures (Nouno & al., 2009). Tools such as linear predictive coding, vocoders, and concatenative synthesis allow composers to dissect, reassemble, and re-synthesize fragments of vocal sound with extraordinary precision, creating textures that evoke not just “the voice” in the abstract, but specific modes of human vocal expression (Traube & Depalle, 2004). As a result, the boundary between speech and music is often deliberately blurred, and the voice appears not as an idealized metaphor but as a physically embodied, technologically mediated presence within the sonic fabric of a composition (Bolaños, 2015). This reconceptualization of vocality is evident in works that embed the voice within the instrumental ensemble, not merely as an expressive influence, but as a source model to be computationally analyzed, reinterpreted, and orchestrally projected.
In more recent compositional practice, a wide range of experimental and technological tools, such as spectral analysis, formant-based modeling, and concatenative synthesis, have enabled composers to explore vocal imitation from a variety of highly specific and nuanced angles (Nouno et al., 2009; Traube & Depalle, 2004). These approaches engage not only with the lyrical voice but speech, cries, screams, whispers, and other vocal gestures. Works like Jonathan Harvey’s Speakings (2007–08) and works from Peter Ablinger’s “talking piano” series, such as Deus Cantando (God, singing) (2009) exemplify this trend, as do numerous other pieces that foreground the timbral, mechanistic, and texturally expressive features of vocal production.
Goals of the Present Study
Our present study aims to evaluate the perceptual robustness of vocality as a feature of instrumental music, despite the historical and contemporary importance of each work. This project, which is funded by a Research-Creation grant from the ACTOR (Analysis, Creation, and Teaching of Orchestration) Project, consists of a perceptual experiment from which a compositional methodology will be derived. This methodology informs a newly commissioned work for ensemble and electronics by Louis Goldford, which is currently in development and scheduled for future performance. While the composition draws conceptually on the findings of this study, it is not analyzed in the present report.
Research Questions
This research explores several interrelated questions about the concept of vocality in instrumental music. First, it asks whether vocality is a relevant or salient feature from the perspective of listeners, distinguishing this perceptual aspect from the creative intentions of composers and performers. If vocality does play a significant role in how instrumental music is perceived, the study further investigates which specific properties of musical sound contribute to this perception, such as timbral characteristics or notated performance techniques like vibrato and legato phrasing. Finally, the research considers whether classical and contemporary approaches to voice-inspired instrumental music are equally effective, or perhaps equally ineffective, in evoking a sense of vocality for listeners.
Methodological Framework
To answer our research questions, we implemented a two-pronged methodology consisting of (1) real-time perceptual ratings by listeners, and (2) subsequent expert analyses of the musical excerpts based on those ratings. First, participants provided continuous slider-based ratings indicating how “voice-like” they perceived each excerpt to be in real time. These ratings captured participants’ subjective impressions of vocality, grounded in their own internal definitions and perceptions. Second, after collecting these listener-based vocality ratings, our team of experimenters undertook a detailed score-based and acoustic analysis of the musical passages, with the goal of identifying specific musical, spectral, or gestural features that aligned with the peaks and troughs in the participant data. This component functioned as a reverse-engineering process: rather than directing listener attention to specific musical cues, we used the collected data to retrospectively identify possible causes for high or low perceived vocality in each excerpt. This dual strategy ensured that our conclusions were informed both by listener experience (subjective perception) and by researcher insight (analytical interpretation). In addition, the musical pieces repertoire was selected to reflect three distinct categories: contemporary vocal mimesis techniques, which explicitly evoke vocality using audio analysis and resynthesis paradigms such as spectral transcription and formant modeling; classical approaches to vocality, which employ traditional performance conventions such as cantabile and recitativo; and control stimuli, which were materially similar in texture and technique but not explicitly intended to evoke the voice. These excerpts were further organized by instrumentation into three groups: solo piano, solo strings, and mixed larger ensembles.
Hypotheses
We hypothesize that listener ratings of vocality will be significantly higher for excerpts composed with vocal models than for control excerpts without explicit vocal references. Previous research suggests that listeners are sensitive to vocal-like qualities in instrumental music, particularly when timbral or expressive cues mimic the human voice (Huron, 2014). We further expect that these higher vocality ratings will be associated with specific features in the musical pieces, either symbolic elements notated in the score or acoustic and signal-based properties identifiable through spectrograms and related analyses (McAdams & Giordano, 2008). Thus, through the experimenters' analysis we aim to identify the specific cues, structural, gestural, or spectral, that may underlie these listener responses.
In parallel, we hypothesize differences across instrumental groupings. String instruments, for example, are widely considered well-suited for dynamic nuance and expressive timbral blending, qualities associated with vocality (Askenfelt, 1991; Schubert & Wolfe, 2016). As such, we expect string excerpts to score highly among our listeners. By contrast, the solo piano may be relatively limited in its potential to project vocality due to its fixed pitch structure and limited ability to articulate extremely soft dynamics (Rink, 2002). Mixed ensembles may present unique opportunities for timbral fusion, though it remains an open question whether large aggregates can convincingly evoke the presence of a single, monophonic voice (Sandell, 1995).
Ultimately, differences observed between historical and contemporary styles, instrumentation types, and technological integrations may be explained by the presence, or absence, of salient features perceived by listeners. These may include vowel-like formant structures in instrumental textures (Traube & Depalle, 2004), speech-like rhythms or breath-like phrasing (Patel, 2008), and notated performance indications such as vibrato or legato cantabile, which have deep historical ties to vocal repertoire and expressive practice (Bowser, 2015). Here, we anticipate finding notable patterns across stylistic categories, where classical and historical repertoire often idealizes lyricism, while contemporary works explore more abstract or mechanistic renderings of speech-like material (Leech-Wilkinson, 2009; Noble, 2022).
Methods
Participants
A total of nineteen participants, 10 who self-identified as women and 9 who self-identified as men, completed the study. Participants were between the ages of 20 and 54 years of age, with a mean age of 31.1 years. 12 Participants were currently enrolled in music degree programs, 2 had extensive private training (5+ years), and 5 were non-musicians. Normal hearing was first assessed at the beginning of our experiment using pure-tone audiometric tests. Participants displayed no history of psychiatric or neurological disorders. The study took approximately 20 minutes to complete and each participant was compensated with a payment of $15 for their responses.
Stimuli
The stimuli (n = 12) are 18–26s in duration and are organized along a 3x3 design with 2 factors (Table 1): Vocality (Contemporary / Classical / Control) x Instrument (Piano / Strings / Mixed ensemble):
Contemporary-vocality. Three excerpts were extracted from contemporary instrumental and electroacoustic music that explicitly sought to evoke vocality through technological means, especially including techniques related to audio analysis and resynthesis paradigms, such as spectral transcription and formant modelling. In this category, we include only pieces whose grounding in vocality is documented by the composers or for whom it is known that the voice functions as a crucial model.
Classical-vocality. Three excerpts were extracted from historical music (i.e., Baroque, Classical, Romantic; hereafter labeled ‘Classical’) which evoke vocality through established performance conventions (e.g., cantabile, recitativo, arioso, etc.). In this category, we include only pieces that make specific references to vocality in their titles and/or performance instructions, or that are documented within scholarship as emulating vocality.
Control (non-vocality). Three excerpts were extracted from contemporary and historical instrumental music that do not intentionally invoke vocal metaphors. In this category, we include only pieces that make no specific references to vocality in their titles or performance instructions. We chose only pieces that we judged to be more straightforwardly ‘instrumental’ in character through figuration, agility, textures, and so forth, yet these are often examples of the same textures and compositional techniques used to structure pieces that are more directly inspired by or derived from the voice.
For each vocality category, the three excerpts were chosen so they would belong in one of these three instrumentation classes: Piano, Strings or Mixed ensemble, differing across historical periods. Our excerpts were chosen based on the availability of known musical excerpts employing vocal models, which happen to cluster into these rough categories based on instrumentation. Works for piano and strings are essentially solo works, while mixed ensembles were scored either for orchestra or large ensemble with electronics, or orchestra and oboe. Musical excerpts were cropped from whole musical audio files using Adobe Audition, sourced from YouTube. No additional treatments were imposed on the original audio files (i.e., .wav files at 48000 kHz; 2304 kbps).
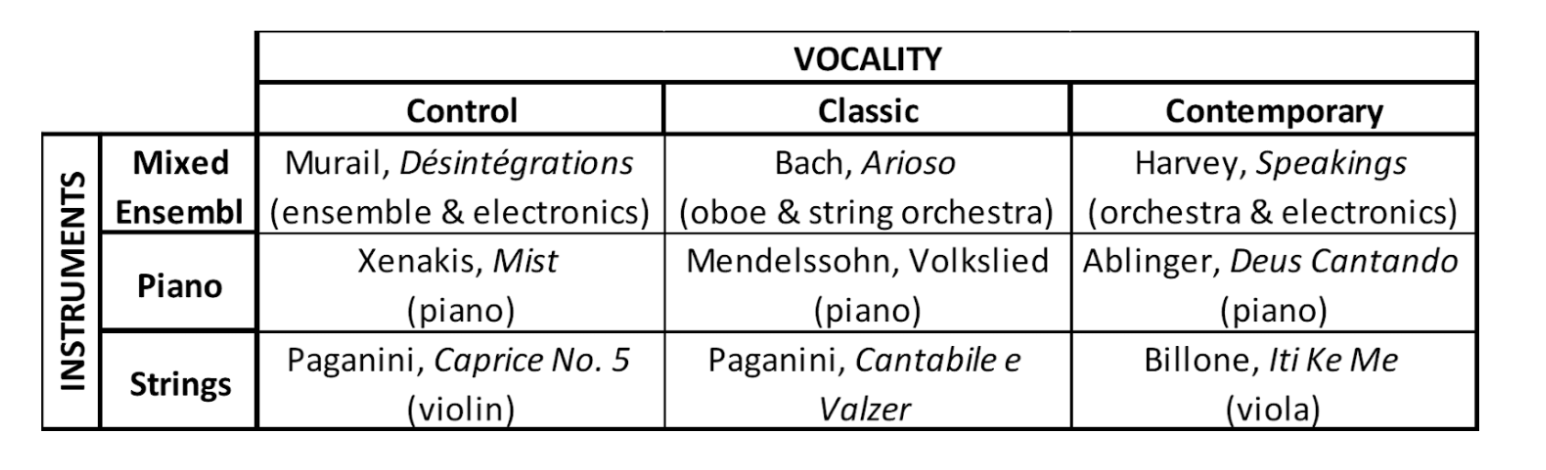
Table 1: Musical excerpts organised along a 3 x 3 design with 2 factors (Table 1): Vocality (Control / Classic/ Contemporary) x Instruments (Mixed ensemble / Piano / Strings).
Apparatus
Sounds were stored and synthesized on a Mac Pro computer running macOS 10.13.6 (Apple Computer, Inc., Cupertino, CA), amplified through a Grace Design m904 monitor (Grace Digital Audio, San Diego, CA), and presented over Sennheiser HD280 Pro earphones. The experimental session was run with the PsiExp computer environment (Smith, 1995).
Procedures
Audiometric test
Before the experiment, participants completed a pure-tone audiometric screening at octave-spaced frequencies ranging from 125 Hz to 8 kHz, in accordance with ISO 389–8 standards (ISO, 2004; Martin & Champlin, 2000). Only those with hearing thresholds at or below 20 dB HL across all tested frequencies were allowed to proceed with the experiment.
Vocality rating
While listening to the stimuli, participants used a slider to rate in real time the extent to which the music evokes vocal qualities or metaphors of vocality. Participants were informed that their answer can change continuously throughout the excerpt, and that the position of the slider should indicate how “vocal” the listener perceives the music to be, or how well the instrumental sounds may seem to mimic vocal traces or qualities, according to their personal definition of vocality (i.e., their own perceptions of the presence of a voice within instrumental music), at any present moment in the excerpt. The poles of the scale were labelled ‘not vocal at all’ at the bottom and ‘extremely vocal’ at the top. They were not given explicit markers of vocal sounds or traits (i.e., vibrato, audible breathing, round vs. nasal tones, etc.) upon which to base their responses, in keeping with methodological approaches in psychoacoustics (Yost, 2015). Once we were able to examine peaks and dips in the average ratings, we looked at various factors in the symbolic score and acoustic spectra, to see what could be related back to objective markers in the composers’ indications (score analysis) and to the performances by interpreters (spectra).
Data Analysis
Data preprocessing
For each participant and for each musical excerpt the rating vector was first interpolated to a temporal resolution of 10 ms. We then removed any time-point for which the standard deviation or its derivative was more than 3 as compared to the participant rating mean, in order to remove sudden momentary changes in slider position unrelated to the rating task. We finally normalized and rescaled every vector to be centered around -100% and 100%, where -100% represents no vocality at all and 100% represents high vocality. Four participants were excluded from analysis due to technical issues that affected data quality.
Statistical comparison of mean behavioral vocality ratings
For each excerpt, we first averaged the vocality rating of each participant, resulting in one vocality score per excerpt and per participant. These data were then submitted to a repeated-measures ANOVA with two within-subject factors: Vocality style (Contemporary / Classical / Control) × Instrument (Piano / Strings / Mixed ensemble). This analysis was used to assess whether perceived vocality differed systematically across musical styles and instrumentations, and whether there was any interaction between these two factors. When the ANOVA revealed significant main effects or interactions, we performed post-hoc tests consisting of pairwise comparisons between conditions using two-tailed t-tests, to identify the specific sources of these effects.
Computational approaches
In addition to our behavioral ratings, we used computational tools to extract computational features directly from the musical excerpts. Here, we aimed to complement the behavioral rating in finding computational signatures for the vocality parts of our excerpts. To do so, we first computed spectrograms that permitted a direct visual inspection of the whole frequency spectrum, as human voices are usually found within a very specific frequency range (~100 - 200 Hz), so we may have some spectral information within this range.
We also computed the Mel Frequency Cepstral Coefficients (MFCCs) using the MIR toolbox (Lartillot et al., 2007) within continuous time-windows of 100 ms. The MFCCs are among of the dominant features used for speech recognition and are also used in modeling music (Logan, 2000). Here, we used only the 1st MFCC coefficient, as it is known to capture the overall shape of the vocal tract spectrum (e.g., first formants F1, F2), and is related to vowel quality and phoneme identity (Rabiner & Schafer, 2010). We then performed representational similarity analysis (RSA) as follows. For each musical excerpt, we first computed one unique MFCC by excerpt. Then, separately for the behavioral ratings and the MFCC coefficient, we computed the Euclidean distances between each excerpt, which we organized as representational dissimilarity matrices (RDMs). We finally correlated the RDMs of the behavioral ratings with the RDMs of the MFCC coefficient using a Pearson correlation.
Experimenter evaluation of the behavioral vocality rating
The vocality human ratings were divided between two experimenters based on their domain of expertise. J.M.K. (Experimenter 1) focused on Classical excerpts, while L.G. (Experiment 2) focused on Contemporary excerpts. They first evaluated the vocality ratings averaged across all participants and identified significant events during the vocality assessments. They then matched them with the corresponding scores and spectrograms of the musical excerpts. This allowed them to extract specific musical articulations or events that were associated with higher vocality ratings.
Results and Discussion
Statistical comparison of mean behavioral vocality ratings
The repeated-measures ANOVA revealed a significant main effect of Vocality style (F(2,36) = 10.80, p < 0.001, ηp² = 0.38), indicating that listeners rated vocality differently depending on the musical style. In contrast, there was no main effect of Instrument (F(2,36) = 1.65, p = 0.207, ηp² = 0.08), suggesting that, overall, the type of instrument (Piano, Strings, Mixed ensemble) did not consistently influence vocality ratings across all styles. However, importantly we found a significant interaction between Vocality style and Instrument (F(4,72) = 18.72, p < 0.001, ηp² = 0.51). This means that the influence of instrument type on perceived vocality depends on the musical style. Follow-up comparisons showed that both Classical and Contemporary excerpts were rated as significantly more vocal than the Control excerpts (Control vs. Classical: t = 4.53, p < 0.001; Control vs. Contemporary: t = 4.71, p < 0.001), while there was no significant difference between Classical and Contemporary (t = 0.49, p > 0.250). These results support the validity of our vocality ratings and suggest that listeners clearly perceived stylistic vocality in the music. The interaction further suggests that the way instruments contribute to perceived vocality varies between Classical and Contemporary styles. For example, an instrument that enhances vocality in Contemporary excerpts may not have the same effect in Classical ones.
Representational similarity analyses with MFCC
The RSA showed a positive correlation between the behavioral vocality rating and the measure of the MFCC coefficient (rho(19) = 0.43; p = 0.009), showing that the MFCCs are promising computational features to study vocality aspects. This is an important finding, as MFCCs are widely used in speech recognition and music modeling. The 1st coefficient of the MFCC primarily tells us about a spectrum’s overall tilt (i.e., whether the higher partials are weighted more than the lower ones, and consequently, whether a sound is bright or dark). Thus, their alignment with our behavioral data provides additional validation for our approach. Indeed, this suggests that participants’ perceptual vocality ratings are capturing information similar to that represented by MFCCs. These features will be further leveraged in subsequent analyses of vocality characteristics across excerpts.
Experimenter evaluation of the behavioral vocality rating
As shown in Figure 1, we then linked behavioral vocality ratings to annotated musical scores, allowing us to identify the specific articulations that evoked vocality. As expected from the previous statistical analyses, we first see that, overall, the control excerpts have qualitatively lower vocal ratings as compared to all other conditions. We then evaluated the rating of vocality in the temporal dimension.
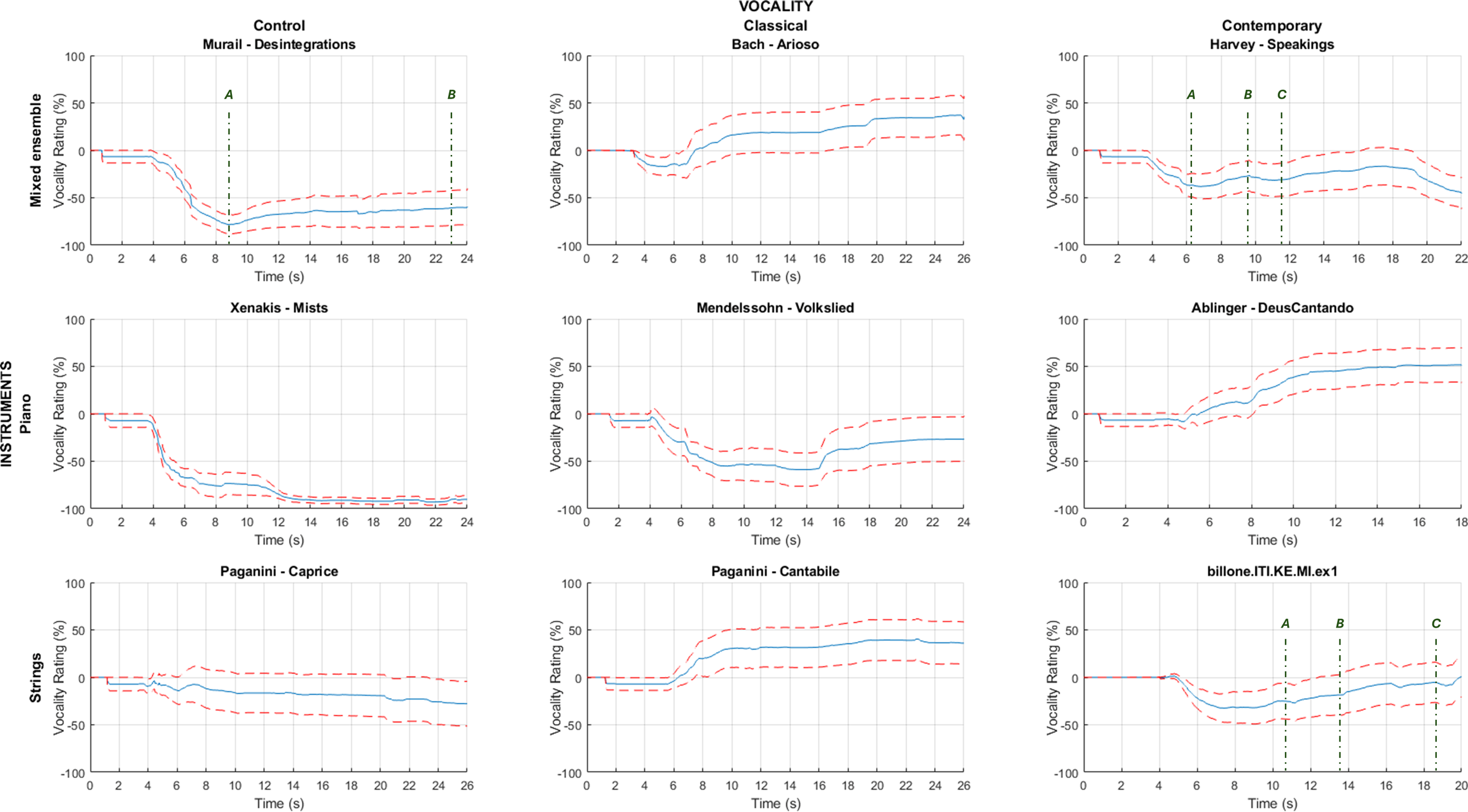
Figure 1. Behavioral vocality ratings for each musical excerpt. Blue lines represent the mean rating of all the participants. Red dashed lines represent the standard error of the means (SEM). Vertical dashed lines with letters represent marker names (A, B, C, etc.), and are referred to in the Discussion text below.
Experimenter 1 Evaluations
Bach, Arioso (Annotated score)

Figure 2. Bach Arioso from Cantata 156,, Annotated Score. Numbers in blue represent seconds, not measure numbers.
The Bach Arioso for oboe and orchestra was one of the highest rated stimuli for vocality. This, we surmise, is at least in part due to the use of vibrato and the audible breathing of the oboe player; two ways in which woodwind playing and singing resemble one another. However, upon closer examination of the excerpt and the specific dips and peaks in vocality ratings, we can point to moments that may have triggered the changes in ratings. For example, at 6.177 seconds, there is a sound played by the continuo that disrupts the flow of the oboe line. This moment was followed by a sharp dip in the rating. At 9.85 seconds, the oboe plays the tonic arpeggio (F5-D5-Bb4) and we see a rise in the vocality rating. At 15.39 seconds, the oboe has an elegant swell on the dominant chord, playing an A4 before resolving to the F. The style of playing here mimics what a singer might do with the line and this precedes an increase in vocality rating. At 18.25 seconds, just before the highest peak in the vocality rating, the oboe has a sustained F5. This is the musical climax of the excerpt and, not surprisingly, leads to the highest rating in the excerpt.
Bach, Arioso (Spectrogram)

Figure 3. Bach Arioso, Annotated Spectrogram
From the singer’s perspective, there is a change in the oboe’s timbre in measure 2, on the F4 landing point from the previous A4 and G4 in measure 1. To mimic what the oboist does, the A and G might be sung on a nasal “in” sound with little vibrato and forward placement, the F would be sung on a “oh” vowel, with vibrato and chiaroscurro (or mid placement), producing a rounder, warmer, or perhaps more of a classic vocal tone. This is visible upon inspection of the spectrogram. From here to the end of the excerpt, the oboist continues to employ this “rounder” tone and the vocality rating rises. We were unable to isolate the oboe part for further acoustic analysis but it would be interesting to confirm, in a future study, whether there is a closer resemblance to a vocal spectrum beginning around the F4 in measure 2 and increasing until the end of the excerpt.
Paganini, Cantabile and Caprice (Annotated scores)

Figure 4. Paganini Cantabile, Op. 19, MS 45, Annotated Score, numbers represent seconds and not measure numbers.

Figure 5. Paganini Caprice, Op. 1, No. 5, Annotated Score, numbers represent seconds and not measure numbers.
In looking at the score, one must first take note of the extremes of range in the Caprice and the speed at which the sweeping gestures are performed. This score is not likely performable by most vocalists. Though some opera singers like Natalie Dessay, Audrey Luna, and Emma Sach are known for performing Ab6 and even C7 and some whistle tone singers like Minnie Riperton (F7) Mariah Carey (G#7), Araina Grande (E7), Prince (G6), Adam Lopez (Eb8) Dimash Qudaibergen (D8), Wang Xialong (E8), Georgia Brown (G10), most singers do not perform notes above E6, which would make the A7 at the 20 second mark unsingable. The Cantabile, on the other hand, could conceivably be sung by a coloratura soprano. Of note as well, are the tempi at which the pieces are to be performed. A quasi adagio is well within the capabilities of the singing voice but the extremely fast tempo of the runs in the caprice, which include skips, are not cleanly performable for most singers. These points alone, even without further consideration, explain the ratings of these two excerpts (Sulaiman, 2023; Ken Tamplin Vocal Academy, 2025).
Paganini, Cantabile and Caprice (Spectrograms)
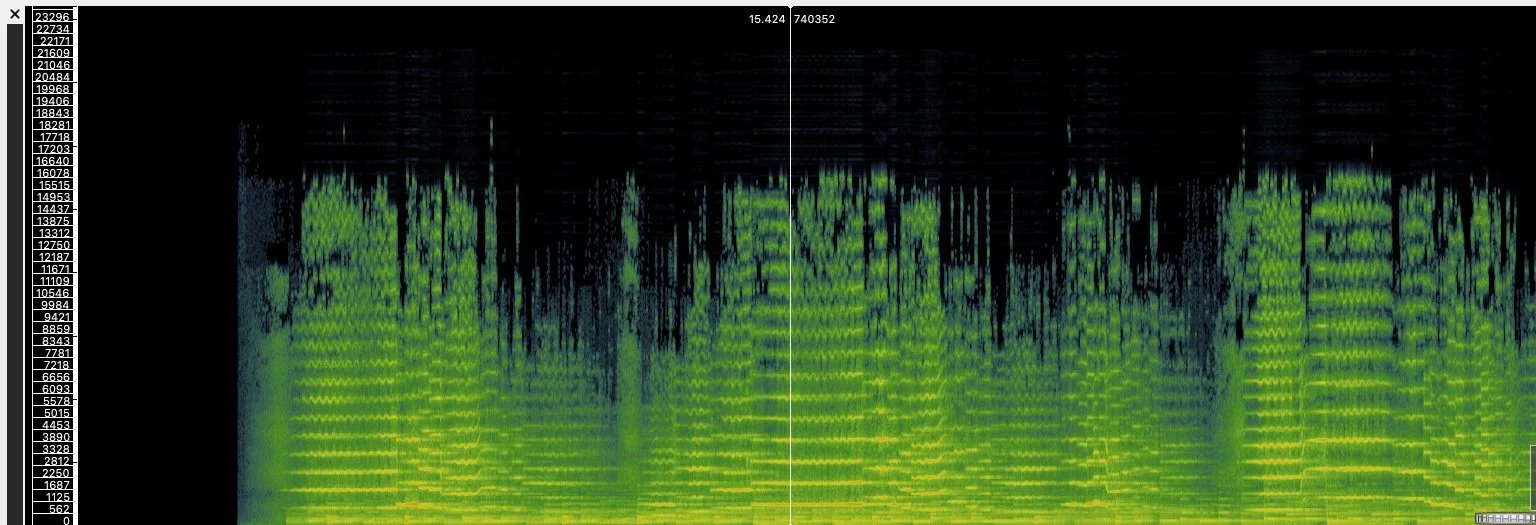
Figure 6. Paganini Cantabile, Spectrogram of excerpt.

Figure 7. Paganini Caprice, Spectrogram of excerpt.
A side-by-side comparison of the spectrographs of the Paganini Cantabile and Caprice already reveals much. Consistent use of vibrato is visible in the Cantabile but in the Caprice, vibrato is used only intermittently. We can also observe the large sweeps and runs in the Caprice (which look like repetitions of the letter U) in the spectrogram. This type of image would be highly unusual in a vocal spectrograph. The Cantabile, meanwhile, displays a more conservative pitch range, which could conceivably be produced by a human voice.
Mendelssohn Volkslied (Annotated score)

Figure 8. Mendelssohn Volkslied, Op. 53, No. 5, Annotated Score, numbers represent seconds and not measure numbers.
Interestingly, the rating for vocality in this excerpt remained low through the introductory material, which is pianistic in style. Once the more legato hymnlike melody enters (meant to evoke singing), around 13 seconds, the rating for vocality begins to increase. Clearly, the vocality ratings here, reflect the intent of the composer.
Mendelssohn Volkslied (Spectrogram)

Figure 9. Mendelssohn Volkslied, Annotated Spectrogram.
We do not see, nor expect to see, traces of vibrato in the spectrograph of a solo piano. Vibrato, therefore, unlike the Paganini excerpts, cannot be attributed to the increasing vocality scores after the Mendelssohn introduction. Here, a look at the score may be initially more revealing for determining why the vocality rating changed around 14 seconds. Mendelssohn uses traditional “hymn style” harmonization and an almost syllabic setting (homorhythmic, homophonic, acapella church hymn setting, where a melody, here, in the tenor and soprano, predominates but there are chordal tones in the alto and bass moving at the same rhythmic pace). Much like in a Bach chorale setting, we can infer singing when the 4-part “sung melody” enters. But we can see clear harmonic peaks that are akin to the resonances of a vocal tract when the “sung melody” enters at approximately 12 seconds. The contribution of each of the notes, harmonically-related, in a 4-part style, result in coincident partials that reinforce certain zones of the spectrum and attenuate others, much like the natural resonances occurring in the vocal tract. For example, at 13 seconds (bar 7), the chord built on C3, A3, E4, and A4 contribute partials that reinforce upper frequencies. If we just consider the first 10 partials on each of these four notes, in the spectrogram we confirm resonances at 440, 660, 880, and 1320 Hz, because they are reinforced and higher in amplitude relative to their surrounding partials.
Experimenter 2 Evaluations
Xenakis, Iannis. Mists (1980) for piano solo
We incorporated a short excerpt from Mists (1980) by Iannis Xenakis, comprising measures 8 through 14 of the solo piano work. This passage features overlapping polyphonic voices in ascending, offset scales that climb in a Shepard-Risset-like fashion. As the phrase progresses toward its culmination in bar 11, the entrances of each new note become increasingly compressed in time—a relative stretto—before arriving at a pause, where the piano resonates under half-pedal. This excerpt was selected as a control in our experiment for its non-vocal portrayal of stochastic “clouds” and waves of ascending activity. As our results confirm, Mists received the overall lowest vocality scores across all excerpts included in our study.
On average, listeners rated Mists progressively lower in vocality as the excerpt unfolded, roughly mirroring changes in intensity (i.e., volume, energy) and event density (i.e., density of new note attack transients). Initially, listeners sharply pulled their sliders downward during the first few seconds of increasingly dense piano music. This motion toward extreme non-vocality then eased gradually over the following 20 seconds. The final 12 seconds show a near-flatline in vocality ratings, reflecting a thinning of note density and a stillness and sustained resonance of the piano during the phrases’ closing moments. Notably, as the onset of each new note becomes more widely spaced, the texture begins to dissolve—much like rainfall in a decaying thunderstorm, where latent heat and kinetic energy are lost as energy dissipates.
In this sparser texture, listeners begin to perceive individual piano notes more distinctly, rather than as a collective mass or cloud of tones forming a complex timbre that might possibly imitate a voice or some other target sound. As the sound approaches the presence and character of a monophonic piano line, the average vocality rating is either dropping or remains in a trough, demonstrating that in the case of a solo piano, vocality may decrease in proportion to sonic density.
Peter Ablinger, Deus Cantando (God, singing) (2009) for computer-controlled piano and screened text
Employing the use of a computer controlled piano designed by Winfried Ritsch alongside software authored by Thomas Musil of IEM Graz, the composer Peter Ablinger’s Deus Cantando (God, singing) is perhaps the strongest example of vocal resynthesis among the excerpts chosen for our study, as our listener ratings confirm. Each key of this piano, however, is operated not by the fingers of a human pianist but by a series of computer-controlled actuators, which are often built from small solenoid motors. Video documentation of this piece and other works in Ablinger’s voice-piano series reveals multiple keys are engaged simultaneously in order to evoke the presence of a monophonic sound source, corresponding to the harmonic and inharmonic partials identified in a partial-tracking analysis of pre-recorded speech. The numerous and simultaneously engaged keys function as constituents of a complex timbre, executed with carefully balanced low amplitude values designed to be heard as a composite sound rather than as individual notes in a chord played by the fingers. Often performed at such quiet dynamic levels that a machine arguably achieves greater subtlety and dynamic control than a human performer, piano tones sum together to approximate the evolving timbres of the pre-recorded target sound. In this case, the audio source is a human vocal reading of the International Environmental Criminal Court declaration. Although the composer provided a score pairing pitches with text, this score serves only as a rough estimate of the work of this complex computer-aided composition and attempts to render a version of the piece playable by a human pianist, filtering out many of the subtle re-articulations of keys and additional pitches necessary to reproduce the voice’s iconic and haunting presence.
Deus Cantando (God, singing) is already a very short piece, but our excerpt introduces its first 16 seconds. Our listeners rated this excerpt exceptionally and consistently high, rising throughout to a value of roughly +50%. Our average ratings report only momentary dips in user-rated vocality that mostly coincide with momentary pauses in the speech at its natural rhythms and rates of execution, serving as short rests in the music. This litmus test for vocality portrayed by an acoustic source, the piano, shows us clearly how a meeting between instrumental resynthesis and advanced uses of software and hardware technology can merge forces to provide an optimum portrayal of the complexities of human vocal timbre.
Tristan Murail, Désintégrations (1982), for instruments and tape
This seminal early work for 17 instruments and tape is one of the most influential examples of live instruments interacting with computer-generated sounds within the repertoire of contemporary “mixed” music, encapsulating many of the principles of spectral composition: analysis-based harmony, the blurring of boundaries between pitch, noise, and resonance, and systematic, formally transformational processes of distortion and stretching. Our excerpt from this piece comprises the measures beginning just after rehearsal II, page 16 of score, where a dense layering of low string, wind, and electronic tremolos and rhythmic trills culminates in one of Murail’s studied instrumental spectra. As indicated in the synthetic notation of electronic audio sources atop the score, this particular aggregate sonority was garnered from the analysis of a flute timbre—notably not a voice. This may explain why our listeners rated the excerpt relatively low, dropping to its lowest value of ~ -75% within its first 9 seconds. The electronic sounds do not, however, trigger a sample playback of a flute recording, but instead appear to resynthesize a few key partial shapes that may have interested the composer, perhaps using additive or FM synthesis, weaved into a texture of tremolos and trills, or measured trill-like figuration, on tempered and microtonally-approximated pitches by the live ensemble, taken from Murail’s instrumental model.
Despite the fact that the source material on which this excerpt is based is primarily non-vocal, our listeners rated the excerpt as progressively more vocal beginning at roughly 8 seconds (Figure 1, marker A), up until about 17 seconds, where this aggregate timbre began to stagnate and our listeners appear to have become ambivalent about whether the effect remained vocal, with ratings lowering before plateauing. Vocality seems to rise gradually before plateauing again at 23 seconds (Figure 1, marker B). Throughout the excerpt, however, the overall scoring remains relatively low as compared to our other ratings, peaking at about -60% by the end, at 24 seconds. The relative rise may be due, at least in part, to the emergence of a vowel format at 8 seconds, as the instruments have all entered and form their composite timbre. Vowel sonorities may occasionally appear in an instrumental aggregate either by intention or by accident. Here, the emergence of a clear “ah” vowel (i.e., “ah” as in the English “father,” or the IPA equivalent /ɑ/, open back unrounded). As the excerpt goes on, however, vocality stagnates with the static persistence of this group sonority, which fails to evolve like a voice and relies heavily on the mechanical nature of its measured, slow trilling between precise microtonal pitches, reinforced by the mechanistic nature of the synthesis. The final plateau at 23 seconds (Figure 1, marker B) may be explained by the introduction of an intruding second sonority that began fading in from niente just beforehand, swelling to mezzo-forte but overpowering the volume of the other forces.
The new aggregate consists of foregrounded brass (trumpet and trombone in plunger mutes) colored by clarinet and bass clarinet. Curiously and unlike the contributions of the instruments that entered previously, this invasive new sonority contains no carefully nuanced microtones and expands to a louder overall dynamic level, with each instrument performing the same dynamic whose culmination is reached at the same moment, as opposed to tiered dynamic arcs, delayed such that each instrument’s maximum volume is reached at different moments, that constructed the first sonority. This new sonority is also relatively more “mechanical,” based on traditional instrumental writing and appears to be detached from a close approximation of an audio analysis model, which crucially obfuscates the vowel-like timbre that preceded it.
Jonathan Harvey, Speakings (2008) for orchestra and electronics
Harvey’s Speakings for large orchestra requires soloists and live electronics and uses specific vocal synthesis techniques to impose the timbres of the human voice on the live sound of the orchestra and its individual instruments. The score draws heavily on a signal processing tool-chain developed primarily at IRCAM in Paris, in which pre-recorded speech is time-stretched with SuperVP, analysed using linear predictive coding (i.e., using LPC formant analyses that approximate the spectral envelope of the voice), while the sound and tempo of the orchestra are followed in real time using the Antescofo software, and the vowel-like timbres of the voice are then “stamped” onto the live orchestral spectrum using Max/MSP and the Gabor software library. As the score was constructed, the Orchidée software helped calculate orchestral chords and colors that already resembled human vowel sounds before any signal processing produces similar effects during an individual performance.
Our excerpt begins on score page 35, rehearsal I, “Senza misura” marking the start of a trombone solo. Listeners are confronted with a single trombone line emerging out of a thickly scored orchestral chord. Our average ratings initially drop over the first 6 seconds of the solo before rising again, with many hills and valleys, before finally decreasing by the end of this excerpt at 22 seconds, at measure 3 on page 36 of score. But what might be responsible for the local dips and bumps in average score as the excerpt progresses?
Notably, ratings begin to increase (Figure 1, marker A) as the first solo trombone glissando approaches its destination F (i.e., just at the ritardando marking), which is the first time we hear an audible contribution from the sampler and SPAT 2 effects chain, which is marked with a “formant” program. These subtle electronic forces, nearly undetectable on their own, color the acoustic trombone sound with vocal formants on top of the trombone timbres. Although computer music specialist Arshia Cont notes the real time usage of LPC analysis (Nouno, Cont et al., 2009), and we might guess that this contribution comes from the SPAT 2 program, one notices two keys executed on a sampler keyboard. A detailed analysis of the production electronics reveals keymappings, a list of audio samples mapped to each key of the sampler keyboard within the orchestra—and the two sound files launched at the start of this trombone solo include the sounds of trombone playing with speech timbres superimposed over the trombone sound. Upon further inspection, it appears that the sounds used in these samples (i.e., of trombone and speech) appear elsewhere throughout the key mappings and can be confirmed individually.
The sample files are built from the spectral envelopes of speech recordings imposed on trombone playing, which lends both the tonal/harmonic shape of vocality along with its prosody (i.e., when the voice pauses between words or syllables or is inaudible, it ducks the original sound of the trombone, thereby creating speech rhythms imposed on the trombone's upper harmonics). To be sure, one cannot be sure whether we are hearing the imposition of speech spectral envelopes by way of LPC analysis or another method, such as SuperVP’s Source-Filter module, but in either case, the computer designers Arshia Cont and Gilbert Nouno (Nouno, Cont et al., 2009) have published widely on their work developed these and similar methods of imposing the spectral envelope of one sound on another.
When comparing these samples to the performance documentation, it appears the samples have been filtered and/or amplitude scaled such that only the upper partials of this trombone are heard over the live trombone. Additionally, the SPAT 2 program seems to have caught the single woodblock attack just before rehearsal I, delaying and diffusing it throughout the concert hall during these first moments of the trombone solo. It is precisely at this point (Figure 1, marker A) where these technological forces combine and first make themselves audible in the course of our excerpt, blended skillfully and seamlessly into the live trombone glissando sound, where our vocality ratings immediately begin to increase. At just after 9.5 seconds (Figure 1, marker B) we notice a decrease in vocality ratings following the second downward glissando of the trombone (i.e., from G to C), which is both louder and more rapid. These sounds are more forcefully instrumental and acoustic, and based on the syntactical acrobatics of trombone playing, and not the voice. Just after 9.5 seconds (Figure 1, marker B), we observe a dip in vocality ratings following the trombone’s second downward glissando (from G to C), which is notably louder and more rapid than the first. Here, the instrument’s idiomatic expressivity—its physicality, acoustic force, and gestural grammar—momentarily asserts itself over the more ambiguous, electronically mediated vocal blend. Here, too, the electronic effects are lost with the increase in the solo trombone’s acoustic volume, so there is no contribution of the synthetic upper trombone harmonics shaped by the synthetic voice analysis. The passage foregrounds the trombone’s historical and acoustic identity rather than its capacity to merge with a mysterious, voice-like spectral envelope. This moment feels quite empty, as all other forces have entirely faded and we are left only with the solo trombone sound. Just after, at roughly 11.5 seconds (Figure 1, marker C), ratings increase once again. Here, as the trombone’s glissandos from a Db-to-C-quarter-sharp, the orchestra returns with piano and winds, later strings, and electronics contributing a similar upper-harmonic spectral envelope shape imitating clear vocal formants. The oboe, in particular, contributes a quality of nasality that blends nicely with this synthesis, enhancing its established nasal vocal qualities.
We find that we cannot attribute the success of any perceivable vocality to the presence of an instrumental solo imitating a voice employing purely acoustic forces, despite that we may only perceive these acoustic forces, but instead the effect is created using a sophisticated signal processing array working in tandem with an instrumental resynthesis, either in solo or in tutti passages.
Pierlugi Billone, ITI. KE. MI (1995) (“New Moon. Mouth. Feminine.”) for solo viola
This curious 30-minute solo viola work, premiered by Barbara Mauer in 1995, is conceived for a retuned viola that reveals the composer’s interest in language and the voice. When Billone asks, “Is it possible to approach music in silent comprehension (without falling prey to the psychological, intuitive, irrational, spontaneous etc., i.e. those forms of comprehension created by speaking)?” he is, without doubt, pointing to a long and established tradition of reduced listening purported by Pierre Schaffer and his disciples that seeks to evoke the presence of a voice without understandable speech.
The piece is scored for solo viola using a parametric notation that defines individual strings and graphical, colored lines representing what Billone defines as separate “states of sound.” In our chosen excerpt, the music is unmeasured with a slow, given tempo range. This passage begins at the bottom of page 1 of the score, third system, at the vocally-evocative marking Respirando, where we begin to hear material that unfolds in short, quasi-syllabic phrasing that resembles vocal utterances or a somewhat natural speech pacing. In this chosen passage, the viola’s strings sound in relative isorhythmic phrases, acting as partial components in an aggregate sound that sums to a complex timbre, sometimes briefly resembling a voice. Here, the colored lines moving between vertical bowing degradations of sul tasto are strictly light-blue, indicating an instrumental tone that is, “round, but not centered; the ‘surface’ of the sound, flautando pressure but with a slow bow” according to an interview with the violist Marco Fusi.
Our listener ratings begin with an initial 4-second decrease until about -30% before a gradual increase over the course of the excerpt’s 20 seconds. Interestingly, and like the Harvey excerpt, average listener ratings increase with many local maxima and minima, but rise to a neutral final score. Within this trend, however, there are some noticeably voice-like moments corresponding to relative local hills and valleys in our vocality scoring data. The first of these is at roughly 10.7 seconds (Figure 1, marker A), where we start to see a larger rise in vocality scores coinciding with a slow, upward glissando of a D harmonic on string II at the same time a fully-stopped F# below it on string III embarks on a similar glissando pathway, along with the temporary disappearance of an ƒ0 fundamental frequency played before and after this short moment on string IV. Though subtle, the relative absence of an ƒ0 places emphasis on the movement of upper partials, which becomes more apparent than the surrounding texture. The listener’s attention may be drawn to the slowly sliding harmonic glissando sound of the upper string, where pitches enter and disappear, delicately touching on the upper string’s nodal points and coloring the fully-stopped lower string. The bow moves in a slow flautando from sul tasto to alto tasto. Flautando bowing introduces subtle noises that are bandpass filtered by the string. Filtering from sul tasto bowing attenuates higher harmonic partials, while the changing impedance across vertical bow positions—combined with the excitation of string modes near nodal points—naturally amplifies and attenuates frequencies within the string’s mid-spectrum. This spectral region may coincidentally align with the dominant resonances corresponding to the first and second formants (ƒ1 and ƒ2) of human speech vowels. This combined effect creates a sensation of moving formant frequencies and shifting human speech vowels. Moments later, at about 13.6 seconds (Figure 1, marker B), we notice a rapid increase in vocality rating coinciding with quasi-speech rhythms marked with tasto position changes as the previous glissando reverses directions at a peak dynamic of piano. With the reentry of ƒ0 on string IV we have a more complete picture of a vocal timbre reasserting itself. However, at 18.6 seconds (Figure 1, marker C), on page 2 of score, top system, we find a sudden and sharp decrease in average rating. The previous vocality effect seems to be ruined by a new glissando of an E harmonic (string II) and G# (string III) where each string is equally foregrounded and balanced in terms of volume and presence. These are not as delicately blended or balanced, preventing a fusing of delicately shifting harmonics into a single timbre. Instead, these strings resemble the notes of a chord rather than the fusing constituents of a timbre.
Conclusion
Our results suggest that naive listeners can reliably perceive vocal qualities in instrumental music, particularly in works composed with explicit vocal models. Through real-time behavioral ratings, computational analysis, and score-based annotation, we identified specific musical features, such as vibrato, speech-like rhythms, formant-like spectral shapes, and dynamic articulations, that we linked with higher vocality ratings. These findings validate vocality as a meaningful and perceptually salient attribute in instrumental music, bridging subjective listener experience with objective musical structure. Ultimately, this research supports the longstanding intuition among composers and performers that instrumental music can evoke the voice, and offers empirical insights to inform both musicological analysis and creative practice.
Future Directions
Future work could expand the set of musical excerpts to include both a larger participant sample size as well as additional works initially considered, incorporate follow-up questions to better understand participant strategies, and increase the study’s current sample size to strengthen statistical power. Planned experiments include a guitar-vowel matching task, where listeners associate vocal vowels with guitar timbres, and acoustic analyses of re-recorded or isolated “vocal” lines to examine features such as spectral centroid and formant structure. In future iterations of these and additional studies we produce, we will also gather crucial participant responses, asking listeners what personal factors contributed to their own vocality rating system. In more controlled experimental settings, we may find it useful to produce and test multitrack recordings in which individual or solo instruments can be evaluated apart from an aggregate mixdown, i.e., acoustically and spectrally, for a time series analysis on audio descriptors (e.g., for computationally derived MFCC ratings, vibrato measures, and other features), which may shed light on the contributions of specific elements within instrumental music.
We also anticipate a performance of the new composition de ce qui nous amène près de vous (2025) for violin, cello, piano, and electronics, by Louis Goldford, commissioned in response to this research. As a result of the exceptionally rated speech rhythms and balanced timbral structures represented with high precision in the Peter Ablinger excerpt, Louis’s new work includes sections of music with carefully analyzed speech excerpts whose vocal formant locations have been carefully scored for a small piano trio, using electronic renderings of the source material’s spectral envelope heard in synchronization with the live instruments, similar to what was found in the Harvey score. Further, we aim to carry out a more comprehensive analysis that will inform one or more submissions to peer-reviewed journals.
References
Allarmunumralla. (2013, February 17). Xenakis - Mists [Video]. YouTube. https://www.youtube.com/watch?v=ZH4j70KU-RQ
Askenfelt, A. (1991). Voices and strings: Close cousins or not?. In Music, Language, Speech and Brain: Proceedings of an International Symposium at the Wenner-Gren Center, Stockholm, 5–8 September 1990 (pp. 243-256). Macmillan Education UK.
Bolaños, G. J. (2015). An Analysis of Jonathan Harvey's" Speakings" for Orchestra and Electronics. University of California, Davis.
Bowser, D. (2015). Mozart's Orchestral Cantabile Style: Eighteenth-Century Origins of String Performance Practices. University of Toronto (Canada).
Day-O’Connell, S. (2014). The Singing Style. The Oxford handbook of topic theory, 238-258.
Ear. (2019, July 9). Deus Cantando. Peter Ablinger [Video]. YouTube. https://youtu.be/Wpt3lmSFW3k?si=7MKNAU_FbJa4BCJx
Healy, K. (2018). Imagined Vocalities: Exploring Voice in the Practice of Instrumental Music Performance (Doctoral dissertation, University of Huddersfield).
Huron, D. (2016). Voice leading: The science behind a musical art. MIT press.
International Organization for Standardization (ISO). (2004). ISO 389‑8:2004: Acoustics — Reference zero for the calibration of audiometric equipment. Part 8: Reference equivalent threshold sound pressure levels for pure tones and circumaural earphones. Geneva, Switzerland.
Ken Tamplin Vocal Academy. (2018, January 15). 20 highest notes ever sung! [Video]. YouTube. https://youtu.be/OUwTyh_Bvtk
Lartillot, O., & Toiviainen, P. (2007, September). A Matlab toolbox for musical feature extraction from audio. In International conference on digital audio effects (Vol. 237, p. 244).
Leech-Wilkinson, D. (2009). The Changing Sound of Music: Approaches to Historical Performance. Cambridge University Press.
Logan, B. (2000, October). Mel frequency cepstral coefficients for music modeling. In Ismir (Vol. 270, No. 1, p. 11).
Marco Fusi. (2022, November 18). ITI KE MI for solo viola (1995) [Video]. YouTube. https://youtu.be/KdkaTkON5RM?si=7jBpsJSqRu-GEFy4
Martin, F. N., & Champlin, C. A. (2000). Reconsidering the limits of normal hearing. Journal of the American Academy of Audiology, 11(02), 64-66.
McAdams, S., & Giordano, B. L. (2008). The perception of musical timbre. Oxford University Press
NewFranzFerencLizst. (2009, 15 December). Barenboim plays Mendelssohn Songs Without Words Op.53 no.5 in A Minor [Video]. YouTube. https://www.youtube.com/watch?v=uRfI42QF0AU
Noble, J. (2022). The career of metaphor hypothesis and vocality in contemporary music. Interdisciplinary Science Reviews, 47(2), 259-278.
Nouno, G., Cont, A., Carpentier, G., & Harvey, J. (2009). Making an orchestra speak. In Sound and music computing.
Patel, A. D. (2010). Music, language, and the brain. Oxford university press.
Rabiner, L., & Schafer, R. (2010). Theory and applications of digital speech processing. Prentice Hall Press.
Rink, J. (Ed.). (2002). Musical performance: A guide to understanding. Cambridge University Press.
Roudet, J. (2014). Frédéric Chopin, Clara Schumann, and the singing piano school. Ohne worte: Vocality and instrumentality in 19th-century music, 65-107.
Sandell, G. J. (1995). Roles for spectral centroid and other factors in determining" blended" instrument pairings in orchestration. Music Perception, 13(2), 209-246.
Schubert, E., & Wolfe, J. (2016). Voicelikeness of musical instruments: A literature review of acoustical, psychological and expressiveness perspectives. Musicae Scientiae, 20(2), 248-262.
Scott St. John - topic. (2014, November 17). Cantabile e Valtz, Op. 19, MS 45 [Video]. YouTube. https://www.youtube.com/watch?v=8HcJnOpdQgo
Sebastian Ars Acoustica. (2015, February 21). Tristan Murail - Désintégrations (1982-83) [Video]. https://www.youtube.com/watch?v=4basuUUatf8
Smith, B. K. (1995, June). PsiExp: An environment for psychoacoustic experimentation using the IRCAM musical workstation. In Society for music perception and cognition conference (Vol. 95). Berkeley, Calif, USA: University of Berkeley.
Sulaiman, M. (2022, March 10). Lovin’ You — Minnie Riperton. In Amazing Moments in Timbre. Timbre and Orchestration Resource. https://timbreandorchestration.org/writings/amazing-moments-in-timbre/2022/3/10/lovin-you
TheExarion. (2013, December 21). Niccolò Paganini - Caprice for Solo Violin, Op. 1 No. 5 (Sheet Music) [Video]. YouTube. https://www.youtube.com/watch?v=c2Wv60_X17A
TheWelleszCompany. (2011, March 13). Jonathan Harvey: Speakings (2007/2008) [Video]. YouTube. https://youtu.be/6UJ2RXIEXa4?si=eJ3PeHVJwj1lfH0a
Traube, C., & Depalle, P. (2004, May). Timbral analogies between vowels and plucked string tones. In 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing (Vol. 4, pp. iv-iv). IEEE.
Voices of Music. (2019, April 24). J.S.Bach - Arioso from Cantata 156 (Sinfonia); Marc Schachman, baroque oboe, Voices of Music 4K [Video]. YouTube. https://www.youtube.com/watch?v=tod_rbkXAHI
Yost, W. A. (2015). Psychoacoustics: A brief historical overview. Acoustics Today, 11(3), 46-53.